

Зачем вообще заморачиваться с превью и тестовыми релизами
Если выпускать фичи сразу в продакшен, рано или поздно всё ломается в самый неудобный момент. Превью-версии и тестовые релизы — это ваш «буфер безопасности»: вы можете показать изменения ограниченному кругу пользователей, собрать обратную связь, поймать баги и только потом катить обновление всем. Фактически, грамотная организация тестового релиза программного обеспечения экономит деньги, нервы и репутацию команды.
По словам тимлида одного из крупных SaaS-сервисов: «Каждый баг, найденный до продакшена, сэкономил нам минимум три часа жизни инженеров и кучу доверия пользователей». Это близко к правде.
Необходимые инструменты: что нужно подготовить заранее
Чтобы тестовые и превью выпуски не превратились в хаос, инструменты важны не меньше, чем сами разработчики. Набор может отличаться, но есть базовый «скелет», который эксперты советуют иметь у любой команды, даже небольшой.
Основные категории инструментов
Держите ориентир на такие виды решений (конкретные продукты выбирайте под свой стек и бюджет):
— Система контроля версий (Git + GitHub / GitLab / Bitbucket)
— CI/CD-платформа (GitHub Actions, GitLab CI, Jenkins, CircleCI и т.п.)
— Платформа для превью-окружений (например, Vercel, Netlify, Railway, Render, Kubernetes с отдельными неймспейсами)
— Система фича-флагов (LaunchDarkly, Unleash, ConfigCat, open-source аналоги)
— Система логирования и мониторинга (Sentry, Grafana, Prometheus, ELK-стек, Logtail и др.)
К ним добавьте чат или таск-трекер, куда будет стекаться вся информация по тестовому релизу — иначе общение расползётся по личкам и мессенджерам.
Инструменты для управления тестовыми и превью релизами
Отдельно имеет смысл подумать про специализированные инструменты для управления тестовыми и превью релизами. Это могут быть надстройки над CI/CD, которые автоматически создают окружение для каждой ветки или pull request, выдают удобный URL превью, подтягивают тестовые данные и чисто удаляют окружение после закрытия задачи.
Эксперты по девопсу рекомендуют сразу стандартизировать: как называется ветка, какие проверки запускаются, куда падают артефакты, кто и как подтверждает, что превью можно превратить в релиз-кандидат.
Как настроить staging и превью: поэтапный процесс
Многие спрашивают, как настроить staging среду для превью версии сайта так, чтобы это не выглядело как «ещё один сервер, где всё кое-как работает». Логика простая: превью-окружения для отдельных фич, staging для сборки релиза целиком, прод — только для проверенного кода.
Дальше — по шагам.
Шаг 1. Продумайте стратегию ветвления
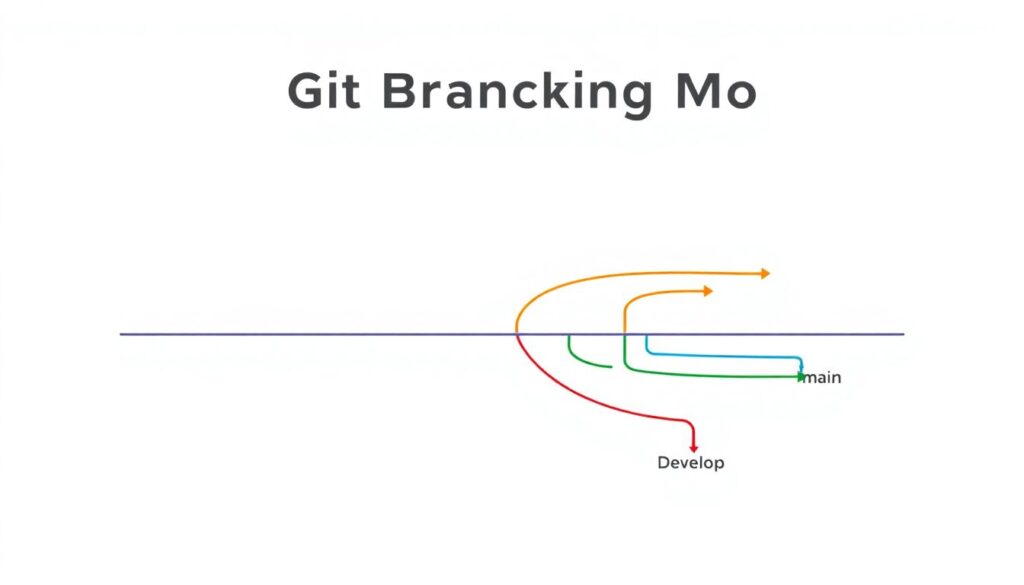
Сначала определитесь, как у вас живут ветки в Git. Без понятной схемы все превью будут рождаться хаотично. Простейшая и жизнеспособная модель:
— `main` / `master` — только стабильный код, максимально близкий к продакшену
— `develop` или аналог — интеграционная ветка для будущего релиза
— feature-ветки — под каждую задачу или фичу
— release-ветки — под конкретный тестовый релиз, если вы идёте по релизным поездам
Один из распространённых советов архитекторов: не городите слишком сложные Git-flow, если команда меньше 20 человек. Простая схема + жёсткие правила ревью обычно дают лучший результат.
Шаг 2. Настройте CI/CD под превью-окружения
Теперь подключаем автоматизацию. При создании pull request или мердж-запроса пайплайн должен:
1. Собрать проект
2. Прогнать тесты (юнит, интеграционные, базовые e2e, линтеры)
3. Поднять превью-окружение (если тесты зелёные)
4. Вывести ссылку на превью прямо в PR
Так вы получите живое превью каждой задачи без участия админа. Обычно это делается с помощью шаблонов пайплайнов: один раз настроили — дальше живёте спокойно.
Шаг 3. Staging как «генеральная репетиция»
Staging-среда — это почти копия прода: те же версии сервисов, похожие конфиги, сопоставимые ограничения. Здесь собирается будущий релиз. Сюда не тащат «сырые» фичи, только то, что прошло код-ревью, тесты и превью-окружения.
Эксперты по качеству продукта часто говорят: если баг не воспроизводится на staging, считать его по-настоящему пофикшенным рано. Это хорошее правило, особенно для сложных систем.
Шаг 4. A/B и превью для ограниченной аудитории
Когда вы уже близки к продакшену, включаются лучшие практики A/B тестирования и превью функций. Здесь в игру вступают фича-флаги: вы раскатываете код на прод, но включаете новые возможности только определённому проценту пользователей или отдельным сегментам.
Это позволяет не только ловить баги, но и измерять реальный эффект: растут ли конверсии, не падает ли удержание, как меняются метрики скорости и ошибок.
Организация тестового релиза ПО: пошаговый сценарий
Чтобы не запутаться, полезно иметь типовой сценарий, как у пожарных: чёткие шаги и роли. Такое описание можно держать в wiki или в репозитории рядом с кодом.
Шаги типового тестового релиза
Пример последовательности:
— Сбор списка задач, которые входят в релиз
— Мёрдж feature-веток в релизную или интеграционную ветку
— Автоматическая сборка и деплой на staging
— Регрессия критического функционала (минимальный чек-лист)
— Проверка аналитики, логов и ошибок
— Демонстрация релиза заинтересованным сторонам (product, support, sales)
— Финальное решение: в прод, на доработку или в заморозку
Один из продакт-менеджеров в интервью говорил: «Я считаю релиз проваленным, если команда не может объяснить, зачем мы его делаем и что будем мерить после выката». Поэтому сразу добавьте к шагам понятный список целевых метрик.
Услуги по проведению пилотного запуска продукта
Если команда маленькая или продукт критичен (финтех, медицина, госуслуги), имеет смысл привлечь внешних экспертов, которые оказывают услуги по проведению пилотного запуска продукта. Они помогают выстроить процессы релизов, настроить observability, подсказать, как не утонуть в баг-репортах и при этом не тормозить развитие.
Даже один разовый аудит релизного процесса может сильно подсветить слабые места: хаотичное тестирование, отсутствие rollback-плана, непонятные критерии «готово к выкату».
Лучшие практики и советы экспертов
Опытные инженеры и продакты обычно сходятся в нескольких идеях: меньше ручного труда, больше прозрачности и чёткое понимание, кто и за что отвечает. Всё остальное — детали реализации.
Краткие экспертные рекомендации
— «Не путайте превью и staging. Превью — песочница для фичи, staging — репетиция релиза», — инженер по надёжности (SRE) крупной e-commerce компании.
— «Каждый тестовый релиз должен иметь цель и метрики успеха. Иначе это просто “ещё один билд”», — старший продакт B2B-сервиса.
— «Учитесь откатывать релизы так же быстро, как выкатывать. Без этого никакие превью не спасут», — девопс-инженер, консультант.
Эти мысли стоит зашить в ваши процессы, а не просто повесить на стену в переговорке.
Что точно стоит внедрить
Если коротко, список приоритетных практик такой:
— Автоматические превью для каждой значимой фичи
— Жёсткое правило: в прод идёт только то, что прошло staging
— Фича-флаги для поэтапного включения функционала
— A/B или хотя бы контроль/эксперимент для важных изменений
— Понятные чек-листы для тестового и боевого релизов
Чем меньше импровизации в критический момент, тем спокойнее живёт команда.
Устранение неполадок: как разруливать проблемы с превью и тестовыми релизами
Проблемы всё равно будут. Разница только в том, всплывут ли они на превью, на staging или уже в проде. Задача — сделать так, чтобы максимальное количество неприятностей останавливалось на ранних этапах.
Типичные проблемы и как их тушить
1. Превью-окружения «падают» или ведут себя нестабильно
— Проверьте, не переиспользуются ли базы данных и сторонние сервисы с конфликтующими данными.
— Ограничьте размеры и время жизни превью-сред: автоматическое удаление после мерджа или закрытия PR.
— Логи и метрики для превью должны быть такими же внимательными, как для прода (хотя бы в упрощённом виде).
2. Staging сильно отличается от прода
— Сведите к минимуму различия в конфигурации: однотипные версии БД, одинаковые фичи, похожие лимиты ресурсов.
— Регулярно синхронизируйте анонимизированные данные: тестировать на пустой базе — самообман.
3. Баги всё равно утекают в прод
— Проанализируйте, почему их не заметили на превью и staging: не хватило тестов, не было сценария, отсутствовали данные.
— Дополните чек-листы и автоматические тесты именно теми сценариями, которые «проскочили».
Эксперты по тестированию советуют относиться к каждому инциденту как к возможности улучшить процесс, а не искать виноватых. Postmortem без охоты на ведьм сильно повышает зрелость команды.
Когда стоит пересмотреть весь процесс
Иногда латать отдельные дыры уже бессмысленно. Сигналы, что пора заново спроектировать цепочку превью → staging → прод:
— релизы регулярно откатываются
— команда боится выкатывать изменения в пятницу (и не только в пятницу)
— бизнес не понимает, когда ждать фичи и почему всё так долго
В таких случаях лучше один раз остановиться, пригласить более опытных коллег или внешних консультантов и переделать релизный процесс, чем годами жить в режиме «вечного пожара».
Итог: простая схема, которой реально пользоваться
Организовать превью и тестовые выпуски — это не про модные слова, а про предсказуемость. Вам нужна понятная схема веток, автоматические превью, внятный staging, фича-флаги и измеримые цели для каждого релиза.
Начните с малого: один нормальный пайплайн, одно стабильное превью-окружение, один аккуратный тестовый релиз с чёткими критериями успеха. А дальше улучшайте по шагам — именно так это делают команды, которые действительно следуют лучшим практикам A/B тестирования и превью функций, а не просто пишут об этом в презентациях.